Loss functions¶
Loss functions are used to train neural networks and to compute the difference between output and target variable. A critical component of training neural networks is the loss function. A loss function is a quantative measure of how bad the predictions of the network are when compared to ground truth labels. Given this score, a network can improve by iteratively updating its weights to minimise this loss. Some tasks use a combination of multiple loss functions, but often you’ll just use one. MXNet Gluon provides a number of the most commonly used loss functions, and you’ll choose certain loss functions depending on your network and task. Some common task and loss function pairs include:
Classification: SigmoidBinaryCrossEntropyLoss, SoftmaxCrossEntropyLoss
Embeddings: HingeLoss
We’ll first import the modules, where the mxnet.gluon.loss module is imported as gloss to avoid the commonly used name loss.
[1]:
from IPython import display
from matplotlib import pyplot as plt
import mxnet as mx
from mxnet import np, npx, autograd
from mxnet.gluon import nn, loss as gloss
Basic Usages¶
Now let’s create an instance of the \(\ell_2\) loss, which is commonly used in regression tasks.
[2]:
loss = gloss.L2Loss()
And then feed two inputs to compute the elementwise loss values.
[3]:
x = np.ones((2,))
y = np.ones((2,)) * 2
loss(x, y)
[04:48:36] /work/mxnet/src/storage/storage.cc:202: Using Pooled (Naive) StorageManager for CPU
[3]:
array([0.5, 0.5])
These values should be equal to the math definition: \(0.5\|x-y\|^2\).
[4]:
.5 * (x - y)**2
[4]:
array([0.5, 0.5])
Next we show how to use a loss function to compute gradients.
[5]:
X = np.random.uniform(size=(2, 4))
net = nn.Dense(1)
net.initialize()
with autograd.record():
l = loss(net(X), y)
print(l)
[2.0564232 2.0480375]
We can compute the gradients w.r.t. the loss function.
[6]:
l.backward()
print(net.weight.grad())
[[-2.0926476 -1.6370986 -1.6798826 -2.2344642]]
Loss functions¶
Most commonly used loss functions can be divided into 2 categories: regression and classification.
Let’s first visualize several regression losses. We visualize the loss values versus the predicted values with label values fixed to be 0.
[7]:
def plot(x, y):
display.set_matplotlib_formats('svg')
plt.plot(x.asnumpy(), y.asnumpy())
plt.xlabel('x')
plt.ylabel('loss')
plt.show()
def show_regression_loss(loss):
x = np.arange(-5, 5, .1)
y = loss(x, np.zeros_like(x))
plot(x, y)
Then plot the classification losses with label values fixed to be 1.
[8]:
def show_classification_loss(loss):
x = np.arange(-5, 5, .1)
y = loss(x, np.ones_like(x))
plot(x, y)
L1 Loss¶
L1 Loss, also called Mean Absolute Error, computes the sum of absolute distance between target values and the output of the neural network. It is defined as:
It is a non-smooth function that can lead to non-convergence. It creates the same gradient for small and large loss values, which can be problematic for the learning process.
[9]:
show_regression_loss(gloss.L1Loss())
/tmp/ipykernel_191919/841998161.py:2: DeprecationWarning: `set_matplotlib_formats` is deprecated since IPython 7.23, directly use `matplotlib_inline.backend_inline.set_matplotlib_formats()`
display.set_matplotlib_formats('svg')

L2 Loss¶
L2Loss, also called Mean Squared Error, is a regression loss function that computes the squared distances between the target values and the output of the neural network. It is defined as:
Compared to L1, L2 loss it is a smooth function and it creates larger gradients for large loss values. However due to the squaring it puts high weight on outliers.
[10]:
show_regression_loss(gloss.L2Loss())
/tmp/ipykernel_191919/841998161.py:2: DeprecationWarning: `set_matplotlib_formats` is deprecated since IPython 7.23, directly use `matplotlib_inline.backend_inline.set_matplotlib_formats()`
display.set_matplotlib_formats('svg')

Huber Loss¶
HuberLoss combines advantages of L1 and L2 loss. It calculates a smoothed L1 loss that is equal to L1 if the absolute error exceeds a threshold
, otherwise it is equal to L2. It is defined as:
[11]:
show_regression_loss(gloss.HuberLoss(rho=1))
/tmp/ipykernel_191919/841998161.py:2: DeprecationWarning: `set_matplotlib_formats` is deprecated since IPython 7.23, directly use `matplotlib_inline.backend_inline.set_matplotlib_formats()`
display.set_matplotlib_formats('svg')

An example of where Huber Loss is used can be found in Deep Q Network.
Cross Entropy Loss with Sigmoid¶
Binary Cross Entropy is a loss function used for binary classification problems e.g. classifying images into 2 classes. Cross entropy measures the difference between two probability distributions and it is defined as:
Before the loss is computed a sigmoid activation is applied per default. If your network has sigmoid activation as last layer, then you need set from_sigmoid to False, to avoid applying the sigmoid function twice.
[12]:
show_classification_loss(gloss.SigmoidBinaryCrossEntropyLoss())
/tmp/ipykernel_191919/841998161.py:2: DeprecationWarning: `set_matplotlib_formats` is deprecated since IPython 7.23, directly use `matplotlib_inline.backend_inline.set_matplotlib_formats()`
display.set_matplotlib_formats('svg')

Cross Entropy Loss with Softmax¶
In classification, we often apply the softmax operator to the predicted outputs to obtain prediction probabilities, and then apply the cross entropy loss against the true labels:
Running these two steps one-by-one, however, may lead to numerical instabilities. The loss module provides a single operators with softmax and cross entropy fused to avoid such problem.
[13]:
loss = gloss.SoftmaxCrossEntropyLoss()
x = np.array([[1, 10], [8, 2]])
y = np.array([0, 1])
loss(x, y)
[13]:
array([9.000123 , 6.0024757])
Hinge Loss¶
Commonly used in Support Vector Machines (SVMs), Hinge Loss is used to additionally penalize predictions that are correct but fall within a margin between classes (the region around a decision boundary). Unlike SoftmaxCrossEntropyLoss, it’s rarely used for neural network training. It is defined as:
[14]:
show_classification_loss(gloss.HingeLoss())
/tmp/ipykernel_191919/841998161.py:2: DeprecationWarning: `set_matplotlib_formats` is deprecated since IPython 7.23, directly use `matplotlib_inline.backend_inline.set_matplotlib_formats()`
display.set_matplotlib_formats('svg')

Logistic Loss¶
The Logistic Loss function computes the performance of binary classification models.
The log loss decreases the closer the prediction is to the actual label. It is sensitive to outliers, because incorrectly classified points are penalized more.
[15]:
show_classification_loss(gloss.LogisticLoss())
/tmp/ipykernel_191919/841998161.py:2: DeprecationWarning: `set_matplotlib_formats` is deprecated since IPython 7.23, directly use `matplotlib_inline.backend_inline.set_matplotlib_formats()`
display.set_matplotlib_formats('svg')

Kullback-Leibler Divergence Loss¶
The Kullback-Leibler divergence loss measures the divergence between two probability distributions by calculating the difference between cross entropy and entropy. It takes as input the probability of predicted label and the probability of true label.
The loss is large, if the predicted probability distribution is far from the ground truth probability distribution. KL divergence is an asymmetric measure. KL divergence loss can be used in Variational Autoencoders (VAEs), and reinforcement learning policy networks such as Trust Region Policy Optimization (TRPO)
For instance, in the following example we get a KL divergence of 0.02. We set from_logits=False, so the loss functions will apply log_softmax on the network output, before computing the KL divergence.
[16]:
output = mx.np.array([[0.39056206, 1.3068528, 0.39056206, -0.30258512]])
print('output.softmax(): {}'.format(npx.softmax(output).asnumpy().tolist()))
target_dist = mx.np.array([[0.3, 0.4, 0.1, 0.2]])
loss_fn = gloss.KLDivLoss(from_logits=False)
loss = loss_fn(output, target_dist)
print('loss (kl divergence): {}'.format(loss.asnumpy().tolist()))
output.softmax(): [[0.19999998807907104, 0.5, 0.19999998807907104, 0.09999999403953552]]
loss (kl divergence): [0.025424206629395485]
Triplet Loss¶
Triplet loss takes three input arrays and measures the relative similarity. It takes a positive and negative input and the anchor.
The loss function minimizes the distance between similar inputs and maximizes the distance between dissimilar ones. In the case of learning embeddings for images of characters, the network may get as input the following 3 images:

The network would learn to minimize the distance between the two A’s and maximize the distance between A and Z.
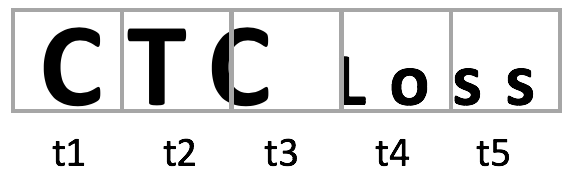
CTC Loss¶
CTC Loss is the connectionist temporal classification loss . It is used to train recurrent neural networks with variable time dimension. It learns the alignment and labelling of input sequences. It takes a sequence as input and gives probabilities for each timestep. For instance, in the following image the word is not well aligned with the 5 timesteps because of the different sizes of characters. CTC Loss finds for each timestep the highest probability
e.g. t1 presents with high probability a C. It combines the highest probapilities and returns the best path decoding.
Cosine Embedding Loss¶
The cosine embedding loss computes the cosine distance between two input vectors.
Cosine distance measures the similarity between two arrays given a label and is typically used for learning nonlinear embeddings. For instance, in the following code example we measure the similarity between the input vectors x and y. Since they are the same the label equals 1. The loss function returns
which is equal 0.
[17]:
x = mx.np.array([1,0,1,0,1,0])
y = mx.np.array([1,0,1,0,1,0])
label = mx.np.array([1])
loss = gloss.CosineEmbeddingLoss()
print(loss(x,y,label))
[0.]
Now let’s make y the opposite of x, so we set the label -1 and the function will return
[18]:
x = mx.np.array([1,0,1,0,1,0])
y = mx.np.array([0,1,0,1,0,1])
label = mx.np.array([-1])
loss = gloss.CosineEmbeddingLoss()
print(loss(x,y,label))
[0.]
PoissonNLLLoss¶
Poisson distribution is widely used for modelling count data. It is defined as:
For instance, the count of cars in road traffic approximately follows a Poisson distribution. Using an ordinary least squares model for Poisson distributed data would not work well because of two reasons: - count data cannot be negative - variance may not be constant
Instead we can use a Poisson regression model, also known as log-linear model. Thereby the Poisson incident rate
is modelled by a linear combination of unknown parameters. We can then use the PoissonNLLLoss which calculates the negative log likelihood for a target that follows a Poisson distribution.
Advanced: Weighted Loss¶
Some examples in a batch may be more important than others. We can apply weights to individual examples during the forward pass of the loss function using the sample_weight argument. All examples are weighted equally by default.
[19]:
x = np.ones((2,))
y = np.ones((2,)) * 2
loss = gloss.L2Loss()
loss(x, y, np.array([1, 2]))
[19]:
array([0.5, 1. ])
Conclusion¶
In this tutorial we saw an example of how to evaluate model performance using loss functions (during the forward pass). Crucially, we then saw how calculate parameter gradients (using backward) which would minimise this loss. You should now have a better understanding of when to apply different loss functions, especially for regression vs classification tasks.
Recommended Next Steps¶
In addition to loss functions, which are used for explicit optimization, you might want to look at metrics that give useful evaluation feedback even if they’re not explicitly optimized for in the same way as the loss. You might also want to learn more about the mechanics of the backpropagation stage in the autograd tutorial.